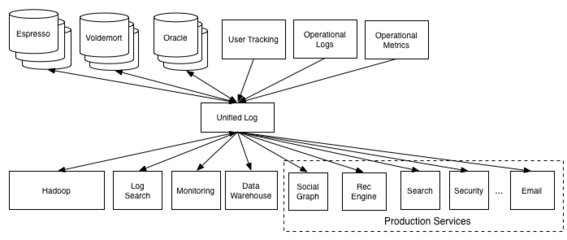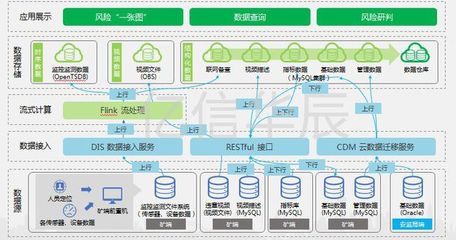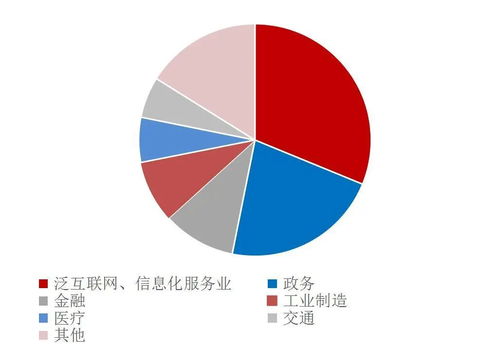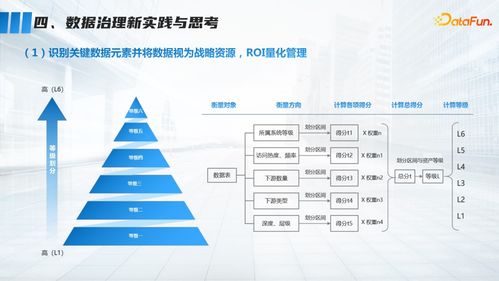
隨著人工智能技術的快速發展,對數據處理與存儲服務的要求日益提高。AI高性能數據服務平臺作為支撐各類智能應用的核心基礎設施,其技術架構的優化直接關系到模型訓練、推理效率及業務創新。本文將重點探討平臺中的數據處理與存儲服務技術,分析其在AI應用中的關鍵作用與發展趨勢。
一、數據處理服務的核心功能
數據處理是AI平臺的基礎環節,主要包括數據采集、清洗、標注、轉換與增強等步驟。高性能數據處理服務通過分布式計算框架(如Apache Spark、Flink)實現海量數據的實時或批量處理,確保數據質量與一致性。例如,在圖像識別應用中,數據增強技術通過旋轉、裁剪等方式擴充訓練集,提升模型泛化能力。同時,平臺集成自動化標注工具,結合主動學習策略,減少人工干預,加速數據準備流程。
二、存儲服務的技術架構
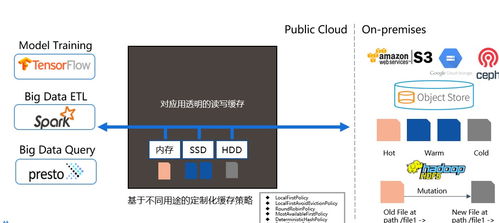
存儲服務是數據平臺的基石,需滿足高吞吐、低延遲與可擴展性需求。AI平臺通常采用分層存儲架構:
- 熱存儲層:使用SSD或內存數據庫(如Redis)存儲頻繁訪問的訓練數據與中間結果,支持高并發讀寫。
- 溫存儲層:基于分布式文件系統(如HDFS)或對象存儲(如Amazon S3)存放歷史數據與模型文件,平衡性能與成本。
- 冷存儲層:利用磁帶庫或低成本云存儲歸檔非活躍數據,實現長期保存。
元數據管理通過專用數據庫(如Apache Hive)記錄數據來源、版本與權限,確保數據可追溯與合規。
三、關鍵技術挑戰與創新
- 數據異構性:AI應用涉及文本、圖像、視頻等多模態數據,平臺需支持統一接口與格式轉換(如Parquet、TFRecord)。
- 實時性要求:流式處理引擎(如Kafka Streams)與內存計算技術保障實時數據分析,滿足在線推理需求。
- 數據安全:通過加密傳輸、訪問控制及隱私計算技術(如聯邦學習)保護敏感信息,符合GDPR等法規。
- 資源優化:利用數據壓縮、緩存策略與彈性伸縮機制,降低存儲成本并提升資源利用率。
四、未來發展趨勢
未來AI數據服務平臺將深度融合云原生與邊緣計算,通過容器化部署與Serverless架構實現靈活調度。智能數據治理工具將借助AI技術自動化數據質量管理,而跨平臺聯邦學習框架則促進數據協作同時保障隱私。隨著量子存儲等新興技術成熟,存儲密度與速度有望實現突破,進一步推動AI創新。
數據處理與存儲服務是AI高性能平臺的命脈,其技術演進不僅提升了算法效率,更賦能各行各業智能化轉型。持續優化數據流水線與存儲架構,將是釋放AI潛力的關鍵所在。