隨著數字化轉型的加速,大數據中心已成為企業信息化的核心支撐。本文基于255頁10萬字的詳細方案,系統闡述大數據中心的整體架構、存儲技術、基礎設施建設及運維管理,并涵蓋數據處理與存儲服務的關鍵內容,文末附123相關資料下載方式。
一、大數據中心整體架構
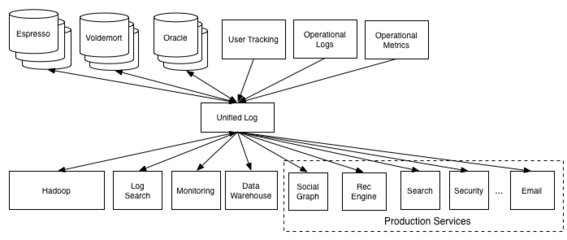
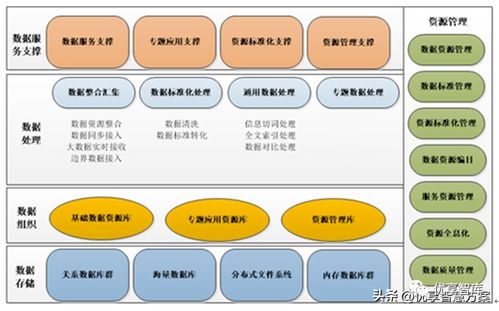
大數據中心架構設計需兼顧可擴展性、高可用性與安全性。典型架構分為接入層、計算層、存儲層和管理層:
- 接入層:負責數據采集與傳輸,支持多種協議與接口。
- 計算層:采用分布式計算框架(如Hadoop、Spark)處理海量數據。
- 存儲層:結合分布式文件系統(如HDFS)與對象存儲,確保數據可靠性與訪問效率。
- 管理層:通過統一平臺實現資源調度、監控與安全管控。
二、存儲方案設計
存儲是大數據中心的核心,需根據數據類型與訪問頻率選擇方案:
- 熱數據存儲:采用SSD或內存數據庫,滿足低延遲需求。
- 溫數據存儲:使用混合存儲技術,平衡性能與成本。
- 冷數據存儲:依托磁帶庫或云存儲,實現長期歸檔。
方案強調數據分層管理、冗余備份與異地容災,確保數據完整性。
三、基礎設施建設要點
基礎設施為大數據中心提供物理保障,關鍵要素包括:
- 電力系統:雙路供電、UPS及柴油發電機,保障99.99%可用性。
- 制冷系統:采用液冷或風冷技術,維持設備在適宜溫度。
- 網絡架構:萬兆以太網與SDN技術,實現高速數據傳輸。
- 安全防護:物理門禁、防火系統與電磁屏蔽,杜絕外部威脅。
四、運維管理策略
運維是確保大數據中心穩定運行的關鍵,涵蓋:
- 自動化運維:通過Ansible、Kubernetes等工具,減少人工干預。
- 監控預警:實時監測硬件狀態與性能指標,及時發現問題。
- 災備恢復:制定RTO與RPO目標,定期演練應急流程。
- 成本優化:通過資源池化與彈性伸縮,控制運營支出。
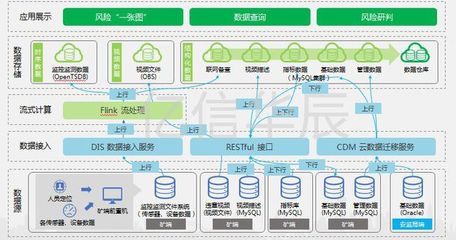
五、數據處理與存儲服務
數據處理服務包括數據采集、清洗、分析與可視化:
- 數據采集:通過Flume、Kafka等工具集成多源數據。
- 數據處理:使用MapReduce或流處理引擎進行實時分析。
- 數據存儲服務:提供結構化與非結構化數據存儲,支持SQL與NoSQL數據庫。
服務設計強調低延遲、高吞吐與合規性,滿足業務多樣化需求。
結語
本方案全面覆蓋大數據中心從架構設計到運維管理的各個環節,幫助企業構建高效、可靠的數據平臺。為便于深入參考,相關資料(包括技術文檔、配置指南及案例庫)可通過以下方式下載:訪問[指定網址],輸入代碼“123”獲取下載鏈接。