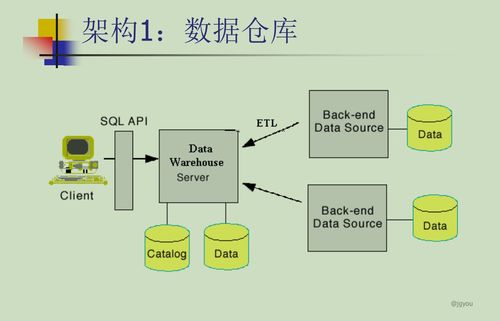
一、數據倉庫的發展歷程
數據倉庫的概念最早由比爾·恩門(Bill Inmon)在1990年提出,他強調數據倉庫是面向主題、集成、非易失且隨時間變化的數據集合,用于支持管理決策。隨著企業數據量的爆炸式增長和技術進步,數據倉庫經歷了從傳統數據倉庫到現代數據湖、云數據倉庫的演變。
- 傳統數據倉庫階段(1990s-2000s):采用ETL(提取、轉換、加載)流程,構建在關系型數據庫上,支持OLAP(聯機分析處理)。但由于成本高、擴展性差,逐漸面臨挑戰。
- 大數據時代(2010s至今):Hadoop、NoSQL等技術的興起催生了數據湖概念,允許存儲結構化與非結構化數據。同時,云數據倉庫(如Amazon Redshift、Google BigQuery)提供了彈性伸縮和低成本服務,推動數據倉庫向實時、智能方向發展。
數據倉庫的發展不僅反映了技術進步,更體現了企業對數據驅動決策的迫切需求。
二、數據倉庫的必要理由
數據倉庫的建設和應用源于企業對高效數據管理和深度分析的需求。其主要理由包括:
- 決策支持:數據倉庫整合來自多個業務系統的數據,提供統一視圖,幫助管理者進行戰略分析和預測。例如,零售企業可通過數據倉庫分析銷售趨勢,優化庫存管理。
- 數據質量與一致性:通過ETL流程清洗和標準化數據,數據倉庫解決了數據孤島和不一致問題,確保報告的準確性和可靠性。
- 歷史數據分析:數據倉庫存儲歷史數據,支持時間序列分析和長期趨勢洞察,這對于風險評估和績效評估至關重要。
- 提升運營效率:自動化數據處理減少人工干預,加快報告生成速度,使企業能夠快速響應市場變化。
- 支持數據挖掘:數據倉庫為高級分析(如數據挖掘)提供高質量數據基礎,助力企業發現隱藏模式和商業洞察。
這些理由共同推動了數據倉庫在企業中的廣泛應用,尤其在金融、零售和醫療等行業。
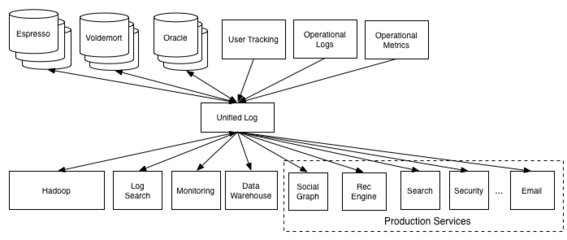
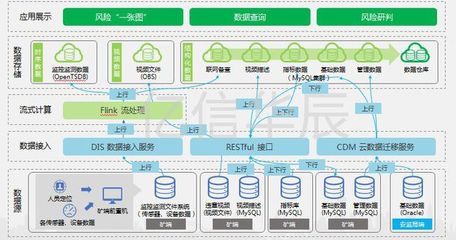
三、數據處理與存儲服務
數據處理和存儲是數據倉庫的核心組成部分,涉及數據采集、轉換、存儲和訪問等多個環節。
- 數據處理服務:主要包括ETL和ELT流程。ETL強調在加載前進行數據轉換,適用于傳統數據倉庫;ELT則利用現代存儲系統的計算能力,在加載后執行轉換,更適應大數據環境。實時流處理技術(如Apache Kafka)的引入,使數據倉庫能夠處理實時數據流,支持即時決策。
- 數據存儲服務:傳統上,數據倉庫依賴于關系型數據庫(如Oracle、SQL Server),采用星型或雪花型模式。現代方案則結合數據湖(存儲原始數據)和數據倉庫(存儲處理后的數據),形成湖倉一體架構。云服務提供商(如AWS、Azure)還提供托管存儲服務,提供高可用性、安全性和成本效益。
這些服務不僅保障了數據的完整性和可訪問性,還通過自動化工具降低了運維復雜度,使企業能夠專注于數據分析而非基礎設施管理。
結語
數據倉庫作為企業數據管理的基石,其發展歷程體現了技術演進與業務需求的緊密結合。通過理解其必要性及核心服務,企業可以更好地利用數據倉庫驅動創新和增長,同時為數據挖掘等高級應用奠定堅實基礎。未來,隨著人工智能和云計算的深入,數據倉庫將繼續演進,成為智能企業的核心引擎。