隨著電子商務(wù)的蓬勃發(fā)展,海量產(chǎn)品評論數(shù)據(jù)成為企業(yè)洞察消費(fèi)者情感和優(yōu)化產(chǎn)品策略的重要資源。基于Python的文本挖掘技術(shù),結(jié)合高效的數(shù)據(jù)處理與存儲服務(wù),能夠系統(tǒng)地對電商評論進(jìn)行情感分析,為業(yè)務(wù)決策提供支持。本報告將詳細(xì)闡述數(shù)據(jù)處理和存儲服務(wù)的核心環(huán)節(jié),包括數(shù)據(jù)采集、清洗、特征提取、情感分析建模以及數(shù)據(jù)存儲方案。
一、數(shù)據(jù)采集與預(yù)處理
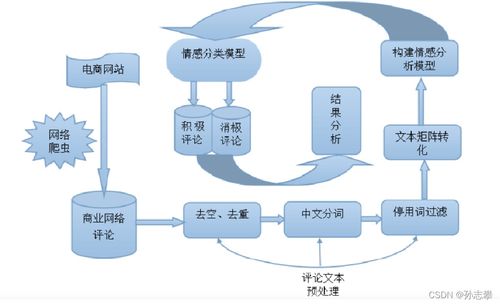
電商平臺的產(chǎn)品評論數(shù)據(jù)通常來源于API接口或網(wǎng)頁爬蟲工具(如Scrapy、BeautifulSoup)。在數(shù)據(jù)采集階段,需確保遵守平臺規(guī)則,避免過度請求。采集到的原始數(shù)據(jù)常包含噪聲,如HTML標(biāo)簽、特殊字符、重復(fù)評論等,因此預(yù)處理是情感分析的基礎(chǔ)。預(yù)處理步驟包括:
- 數(shù)據(jù)清洗:移除無關(guān)字符、停用詞(使用NLTK或jieba庫)和標(biāo)點(diǎn)符號。
- 文本規(guī)范化:統(tǒng)一大小寫、處理縮寫詞和拼寫錯誤,例如通過正則表達(dá)式或spaCy庫。
- 分詞處理:對中文評論使用jieba分詞,英文評論使用NLTK的word_tokenize,將文本轉(zhuǎn)換為詞語序列。
二、特征提取與情感分析建模
在數(shù)據(jù)預(yù)處理后,需將文本轉(zhuǎn)換為數(shù)值特征,以用于機(jī)器學(xué)習(xí)模型。常用的特征提取方法包括:
- 詞袋模型(Bag of Words) 和 TF-IDF:通過sklearn庫的CountVectorizer和TfidfVectorizer實(shí)現(xiàn),捕捉詞語頻率信息。
- 詞嵌入(Word Embeddings):如Word2Vec或GloVe,使用gensim庫生成詞語的分布式表示,適合深度學(xué)習(xí)模型。
情感分析建模通常采用監(jiān)督學(xué)習(xí)或深度學(xué)習(xí)的方法:
- 監(jiān)督學(xué)習(xí)模型:如樸素貝葉斯、支持向量機(jī)(SVM)或隨機(jī)森林,使用已標(biāo)注的情感標(biāo)簽(正面、負(fù)面、中性)進(jìn)行訓(xùn)練。模型評估可通過準(zhǔn)確率、召回率和F1-score等指標(biāo)。
- 深度學(xué)習(xí)模型:如LSTM或BERT,利用TensorFlow或PyTorch框架構(gòu)建,能夠處理長文本和復(fù)雜情感表達(dá)。預(yù)訓(xùn)練模型(如BERT)在電商評論中表現(xiàn)優(yōu)異,但需大量計算資源。
三、數(shù)據(jù)處理與存儲服務(wù)
為確保分析流程的可擴(kuò)展性和效率,數(shù)據(jù)處理和存儲服務(wù)需設(shè)計為模塊化系統(tǒng):
- 數(shù)據(jù)處理流水線:使用Apache Spark或Dask進(jìn)行分布式處理,處理大規(guī)模評論數(shù)據(jù)。流水線包括數(shù)據(jù)清洗、特征提取和模型推理,可通過Airflow或Luigi實(shí)現(xiàn)自動化調(diào)度。
- 數(shù)據(jù)存儲方案:根據(jù)數(shù)據(jù)量和使用場景選擇存儲方式:
- 關(guān)系型數(shù)據(jù)庫:如MySQL或PostgreSQL,適用于結(jié)構(gòu)化數(shù)據(jù)和查詢頻繁的場景,存儲情感分析結(jié)果和元數(shù)據(jù)。
- NoSQL數(shù)據(jù)庫:如MongoDB,適合存儲半結(jié)構(gòu)化的評論原文和情感標(biāo)簽,便于擴(kuò)展。
- 云存儲服務(wù):如AWS S3或Google Cloud Storage,用于備份原始數(shù)據(jù)和中間結(jié)果,支持高可用性。
- API服務(wù)與可視化:構(gòu)建RESTful API(使用Flask或FastAPI)提供情感分析服務(wù),并通過可視化工具(如Tableau或Matplotlib)展示情感分布和趨勢報告。
四、優(yōu)勢與挑戰(zhàn)
基于Python的文本挖掘結(jié)合數(shù)據(jù)處理存儲服務(wù),優(yōu)勢包括:開源庫豐富、成本低廉、易于集成;但挑戰(zhàn)在于數(shù)據(jù)隱私合規(guī)、模型泛化能力以及實(shí)時處理需求。未來,可探索結(jié)合實(shí)時流處理(如Kafka)和邊緣計算,以提升電商場景的響應(yīng)速度。
通過系統(tǒng)化的數(shù)據(jù)處理和存儲服務(wù),電商產(chǎn)品評論情感分析能夠有效挖掘用戶反饋,助力企業(yè)優(yōu)化產(chǎn)品和營銷策略,實(shí)現(xiàn)數(shù)據(jù)驅(qū)動的商業(yè)價值。