在現代Java微服務架構中,數據處理和存儲服務是核心組件之一,而微服務跟蹤則提供了對分布式系統行為的可見性。本文將探討如何設計一個高效的數據處理和存儲服務,并集成微服務跟蹤機制,以確保系統的可擴展性、可靠性和可觀測性。
一、數據處理和存儲服務的重要性
在微服務項目中,數據處理和存儲服務負責管理數據的持久化、查詢和更新操作。這些服務通常基于領域驅動設計(DDD)原則,將數據訪問邏輯封裝在獨立的微服務中,例如用戶服務、訂單服務或庫存服務。采用Java技術棧,常見的實現方式包括:
- Spring Boot框架:提供快速開發微服務的能力,集成Spring Data JPA或MyBatis等ORM工具,簡化數據庫操作。
- 數據庫選擇:根據需求選擇關系型數據庫(如MySQL、PostgreSQL)或NoSQL數據庫(如MongoDB、Redis),支持事務處理和高性能讀寫。
- 消息隊列集成:使用Kafka或RabbitMQ處理異步數據流,確保數據一致性。
數據處理服務需關注數據分片、緩存策略和容錯機制,以應對高并發場景。
二、微服務跟蹤的原理與實現
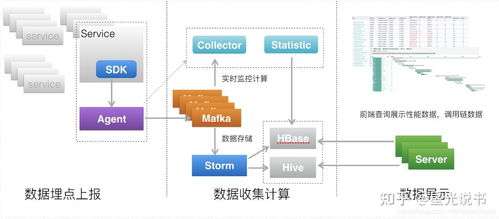
微服務跟蹤(如使用Spring Cloud Sleuth和Zipkin)通過在請求鏈中注入唯一跟蹤ID(Trace ID)和跨度ID(Span ID),記錄每個微服務的調用路徑和延遲。這有助于:
- 問題診斷:快速定位性能瓶頸或錯誤源頭。
- 可視化監控:通過Zipkin或Jaeger等工具展示調用依賴關系。
- 日志關聯:將跟蹤信息與應用程序日志結合,提供完整的上下文。
在Java項目中,集成微服務跟蹤只需添加依賴項并配置追蹤器,即可自動捕獲HTTP請求、數據庫查詢和消息傳遞事件。
三、數據處理和存儲服務與微服務跟蹤的集成
為了提升系統的可觀測性,數據處理和存儲服務應與微服務跟蹤深度集成:
- 數據庫操作跟蹤:利用Spring Data的攔截器或自定義AOP切面,在數據查詢和更新時記錄跟蹤信息,包括SQL執行時間和結果狀態。
- 消息處理跟蹤:在消費或生產消息時,傳播跟蹤上下文,確保異步流程的可追溯性。
- 存儲層監控:結合APM工具(如Micrometer),收集數據庫連接池、緩存命中率等指標,并與跟蹤數據關聯分析。
通過這種集成,開發團隊可以全面了解數據處理服務的性能,例如識別慢查詢或事務超時問題。
四、最佳實踐與挑戰
在實施過程中,需注意以下方面:
- 性能開銷:跟蹤會增加系統負載,應通過采樣率控制數據量,避免影響核心業務。
- 數據安全:確保跟蹤數據不泄露敏感信息,例如通過過濾或脫敏機制。
- 跨服務一致性:在分布式事務中,跟蹤ID需在服務間無縫傳遞,以保持鏈路完整性。
Java微服務項目中的數據處理和存儲服務,結合微服務跟蹤,不僅能提升數據管理的效率,還能增強系統的可維護性。隨著云原生技術的發展,可進一步探索服務網格(如Istio)與跟蹤系統的集成,實現更精細的監控。